🤗hugging face deep reinforcement learning course
Introduction
What is Reinforcement Learning
Reinforcement learning is a framework for solving control tasks (also called decision problems) by building agents that learn from the environment by interacting with it through trial and error and receiving rewards (positive or negative) as unique feedback.
The Reinforcement Learning Framework
reward hypothesis: a goal can be described as the maximization of the expected cumulative reward.
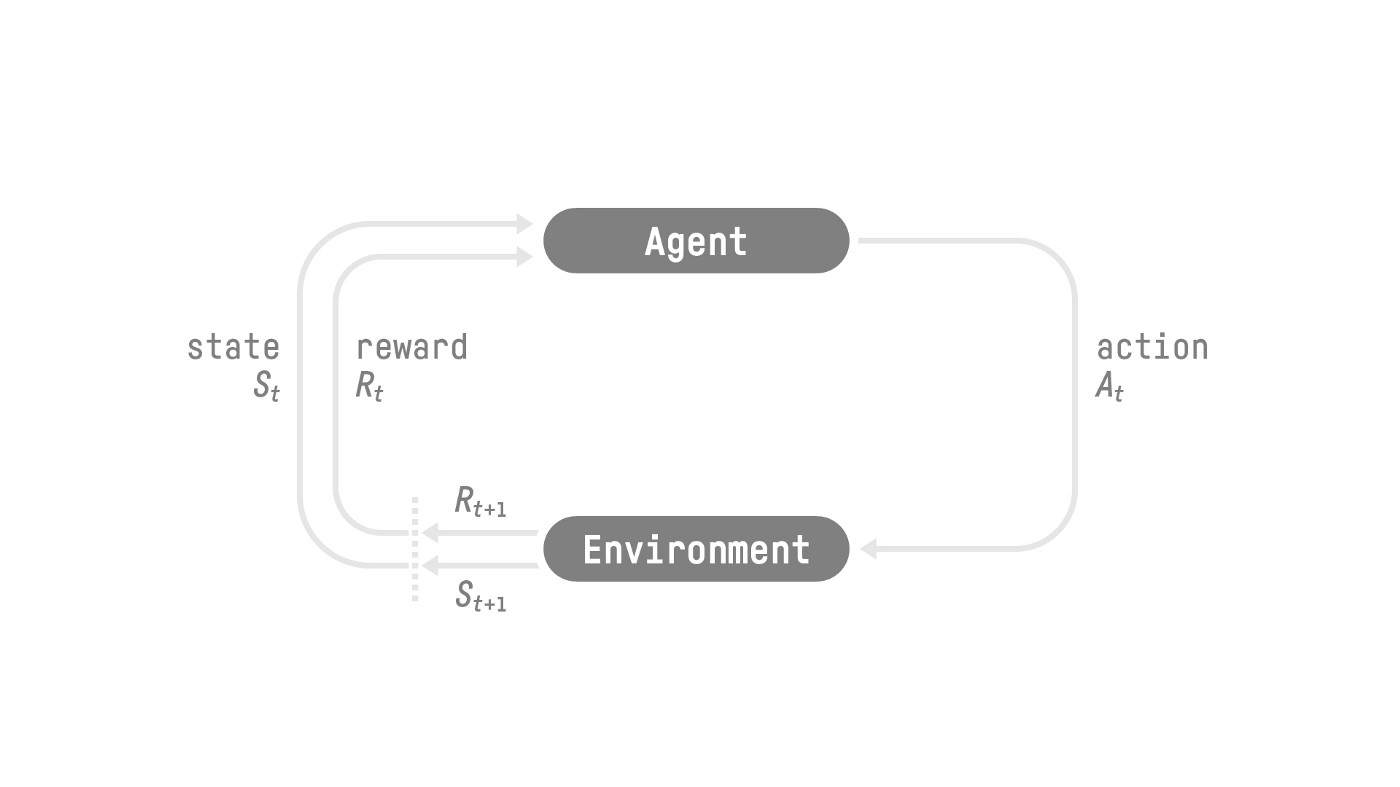
agent needs only the current state to decide what action to take and not the history of all the states and actions they took before.
The RL Process
The reward hypothesis: the central idea of Reinforcement Learning
Markov Property
Observations/States Space
The difference between state and observation.
Action Space
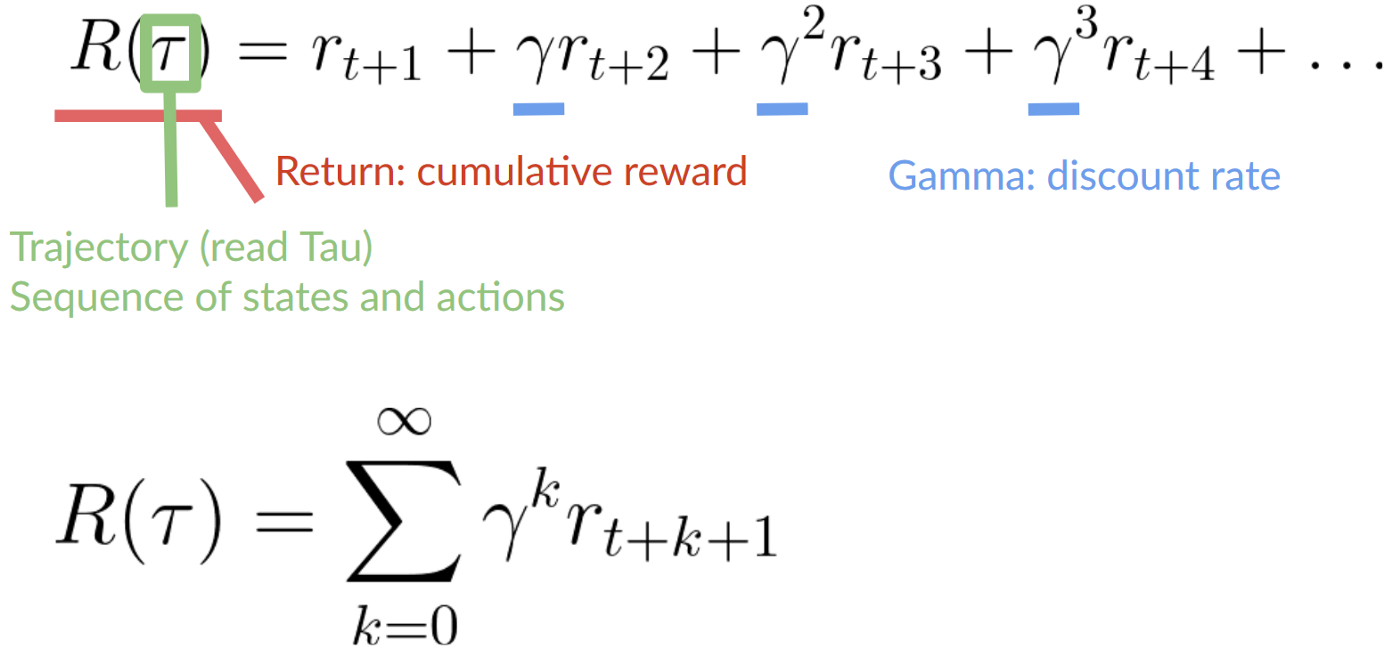
Rewards and the discounting
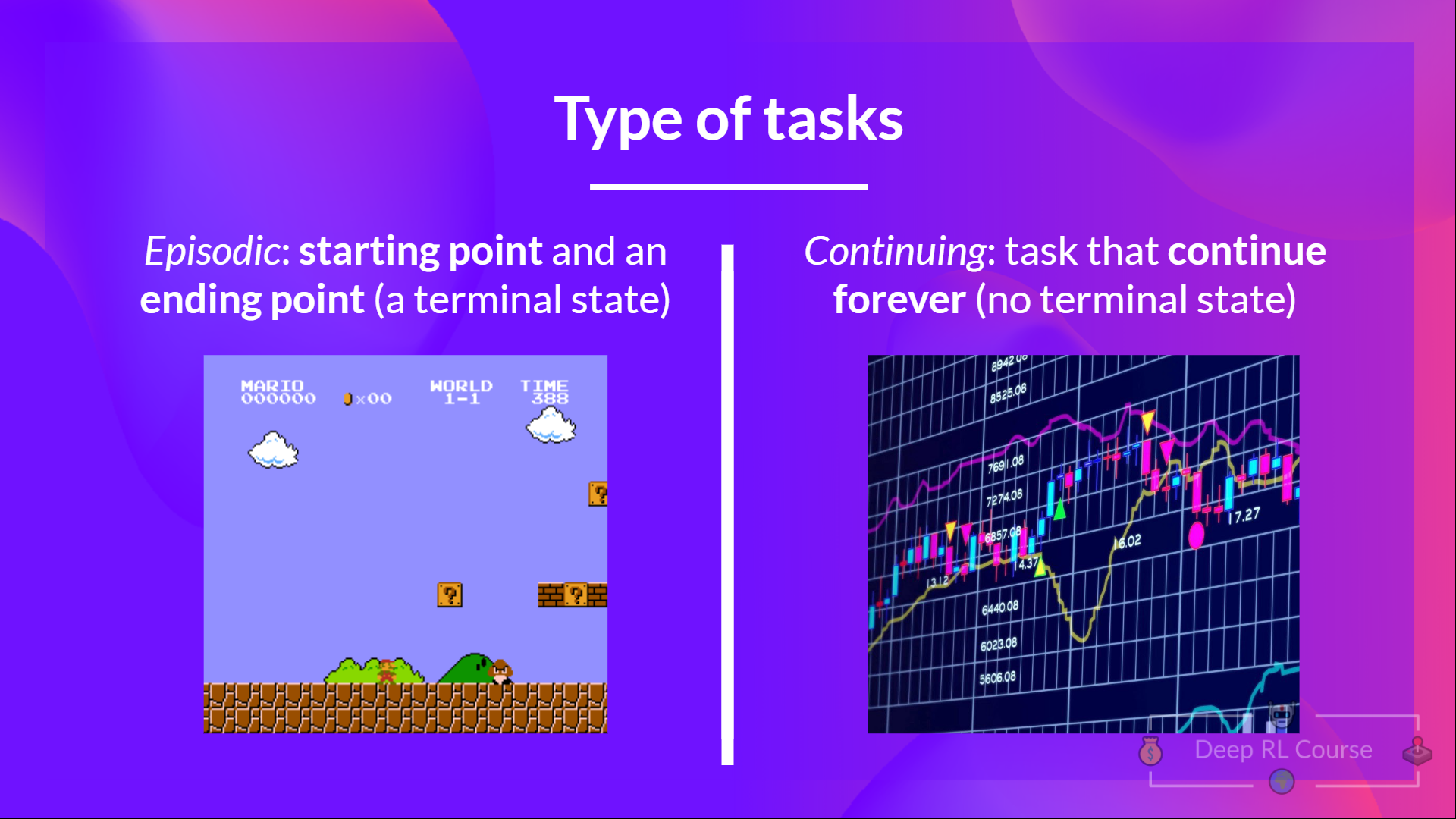
Type of tasks
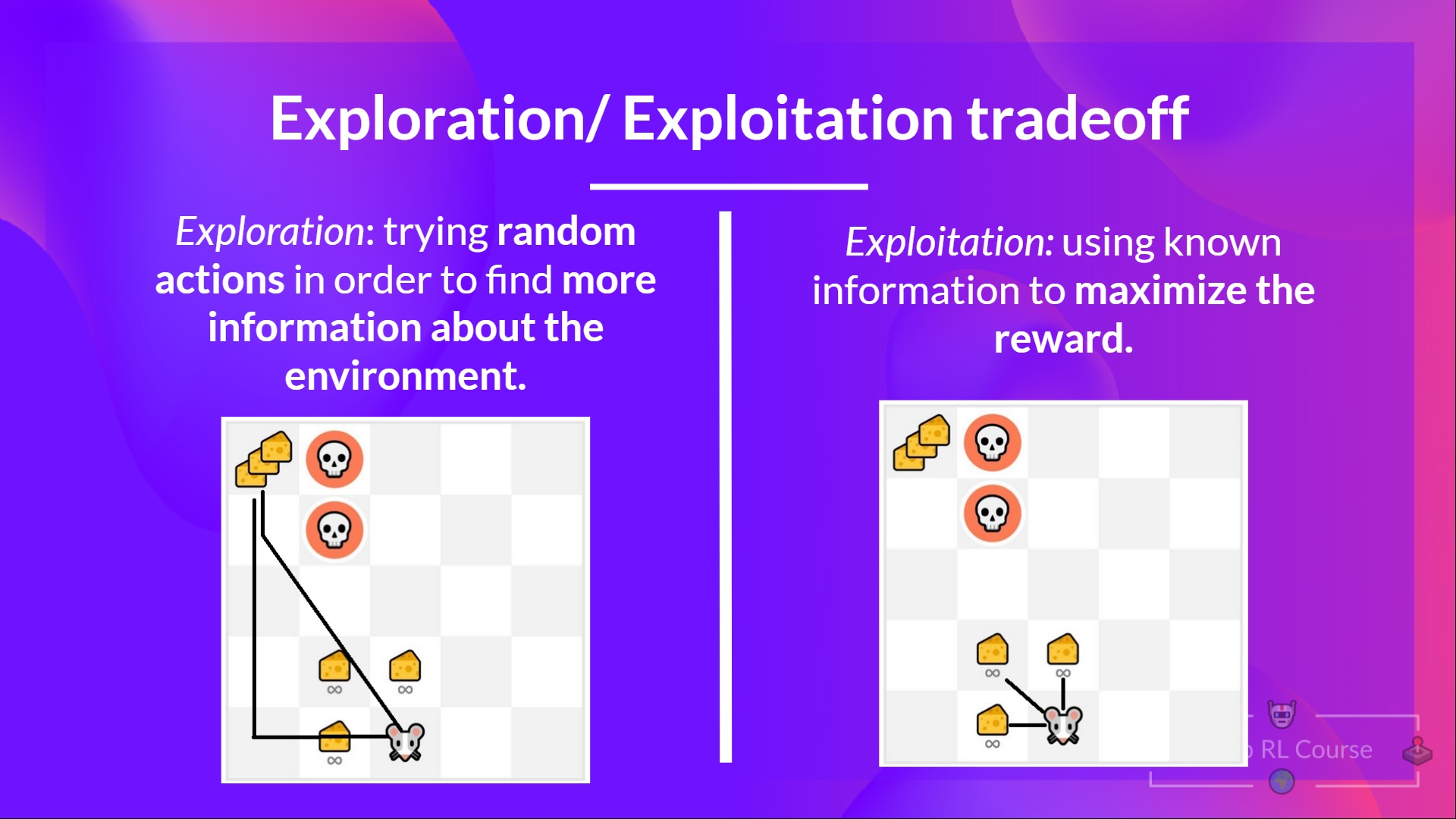
The Exploration/Exploitation trade-off
Two main approaches for solving RL problems
The Policy π: the agent’s brain
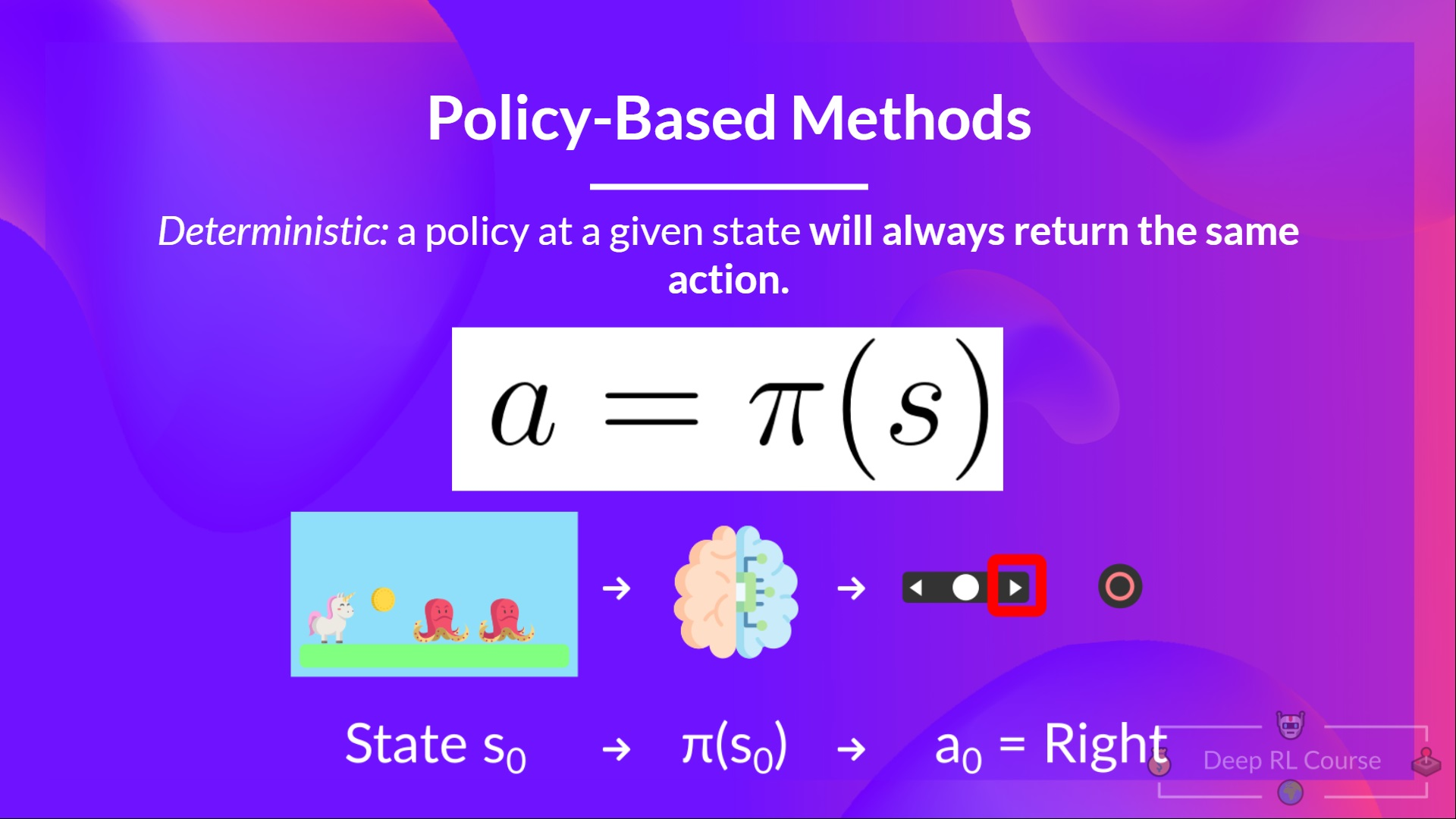
Policy-Based Methods

Value-based methods
The “Deep” in Deep Reinforcement Leaning
Summary
Glossary
This is a community-created glossary. Contributions are welcome!
Agent
An agent learns to make decisions by trial and error, with rewards and punishments from the surroundings.
Environment
An environment is a simulated world where an agent can learn by interacting with it.
Markov Property
It implies that the action taken by our agent is conditional solely on the present state and independent of the past states and actions.
Observations/State
- State: Complete description of the state of the world.
- Observation: Partial description of the state of the environment/world.
Actions
- Discrete Actions: Finite number of actions, such as left, right, up, and down.
- Continuous Actions: Infinite possibility of actions; for example, in the case of self-driving cars, the driving scenario has an infinite possibility of actions occurring.
Rewards and Discounting
- Rewards: Fundamental factor in RL. Tells the agent whether the action taken is good/bad.
- RL algorithms are focused on maximizing the cumulative reward.
- Reward Hypothesis: RL problems can be formulated as a maximisation of (cumulative) return.
- Discounting is performed because rewards obtained at the start are more likely to happen as they are more predictable than long-term rewards.
Tasks
- Episodic: Has a starting point and an ending point.
- Continuous: Has a starting point but no ending point.
Exploration v/s Exploitation Trade-Off
- Exploration: It’s all about exploring the environment by trying random actions and receiving feedback/returns/rewards from the environment.
- Exploitation: It’s about exploiting what we know about the environment to gain maximum rewards.
- Exploration-Exploitation Trade-Off: It balances how much we want to explore the environment and how much we want to exploit what we know about the environment.
Policy
- Policy: It is called the agent’s brain. It tells us what action to take, given the state.
- Optimal Policy: Policy that maximizes the expected return when an agent acts according to it. It is learned through training.
Policy-based Methods:
- An approach to solving RL problems.
- In this method, the Policy is learned directly.
- Will map each state to the best corresponding action at that state. Or a probability distribution over the set of possible actions at that state.
Value-based Methods:
- Another approach to solving RL problems.
- Here, instead of training a policy, we train a value function that maps each state to the expected value of being in that state.